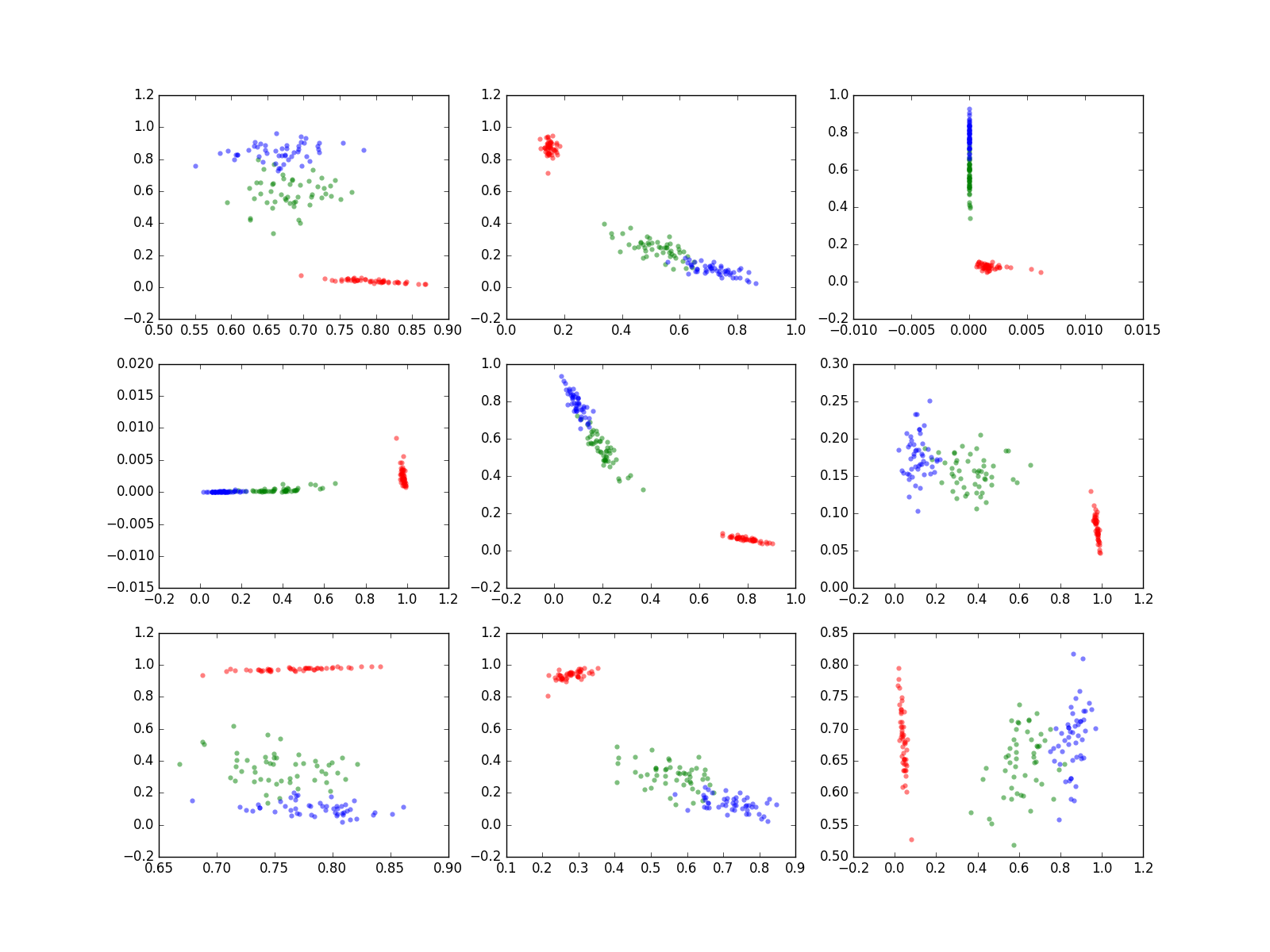
Irisデータで実験したAutoEncoderの、中間層(ノード数2)の中身は次のようになっていた。
各グラフが1回の実験を示し、9回実験したものを並べてみた。
もちろん同じデータで同じ条件で実験したのだが、こんなに違う。
目盛りも図毎にかなり異なる。
つまり、
同じデータを与え、ほとんど似た結果が出ても、中間層の状態は同じにはならない。
中間層は2ノードの層が1つあるだけ。この2つのノードのそれぞれをx軸、y軸とし、Irisの種類にによって、RGBの3色で中間層のノードの値をプロットしてみた。
Irisの種類によって、偏りがあるのがわかる。
とくに、R(赤)は、G、Bとははっきり分かれている。
 では、この図をどうやって作ったか、プログラムの説明をしよう。
では、この図をどうやって作ったか、プログラムの説明をしよう。
今までは、学習し、評価し、それで終わりのプログラムであったが、今回は全データを学習に用い、中間層の中身を取り出して、その中間層の中身を返す関数にオートエンコーダの1回分の処理をまとめ、execonce() とした。
では、このexeconce() を直接実行してみよう。
これを、Irisの種類に応じて色分けして表示すると、何か分かるかも知れない。
ということで、最初に示した図が得られるのだが、そのあたりは次回説明しよう。
各グラフが1回の実験を示し、9回実験したものを並べてみた。
もちろん同じデータで同じ条件で実験したのだが、こんなに違う。
目盛りも図毎にかなり異なる。
つまり、
同じデータを与え、ほとんど似た結果が出ても、中間層の状態は同じにはならない。
中間層は2ノードの層が1つあるだけ。この2つのノードのそれぞれをx軸、y軸とし、Irisの種類にによって、RGBの3色で中間層のノードの値をプロットしてみた。
Irisの種類によって、偏りがあるのがわかる。
とくに、R(赤)は、G、Bとははっきり分かれている。
では、この図をどうやって作ったか、プログラムの説明をしよう。今までは、学習し、評価し、それで終わりのプログラムであったが、今回は全データを学習に用い、中間層の中身を取り出して、その中間層の中身を返す関数にオートエンコーダの1回分の処理をまとめ、execonce() とした。
def execonce():
# Initialize model
model = MyAE()
optimizer = optimizers.SGD()
optimizer.setup(model)
# Learn
n = 150
for j in range(3000):
x = Variable(xtrain)
model.cleargrads() # model.zerograds() は古い
loss = model(x)
loss.backward()
optimizer.update()
# get middle layer data
x = Variable(xtrain, volatile='on')
yt = F.sigmoid(model.l1(x))
ans = yt.data
return ans
では、このexeconce() を直接実行してみよう。
>>> ans = execonce() >>> ans.shape (150, 2) >>> ans[:5] array([[ 0.99554908, 0.00865224], [ 0.99200833, 0.01623198], [ 0.99302506, 0.01248077], [ 0.992621 , 0.02188915], [ 0.99591887, 0.00837815]], dtype=float32) >>>ちゃんとデータ数150個に対し、2つの値が求まっている。
これを、Irisの種類に応じて色分けして表示すると、何か分かるかも知れない。
ということで、最初に示した図が得られるのだが、そのあたりは次回説明しよう。

#人気の記事
#タグ


