並列に Deep Learning して、高速に賢くなれるか
2017年 06月 22日
Deep Learning していると、学習にとても時間がかかるのがネックになる。
時間だけでなく、メモリもいっぱい必要になる。
今はGPUなるものがあり、これを使うと計算処理が一気に早くなると言われている。
GPUの計算性能は、CPUの50倍以上とか言われているのだが、実際にはそこまで高速にDeep Learningできるようにはならない。
GPUを使う場合には、GPUにデータを送ったり、GPUからデータを受け取ったりなど、CPUとGPUの間でのデータのやり取りが発生し、この量が半端ではない。このため、実際の速度向上は10倍程度にしかならない。
でも、もっと高速にしたいと思ったらどうすればよいだろうか。
多数のGPUを同時に使えば、どんどん高速になるのではないだろうか。
分散して学習する場合に問題になるのは、別々のGPUで学習した結果をまとめて、それをまた全GPUに分配し直すという作業が必要である。これをいかに上手にするかで性能が殆んど決まってしまう。
これは人間にたとえると、多人数で勉強をするにの、それぞれ別の参考書を読んで学習し、読み終わったら全員で学習結果を寄せ集めることでより賢くし、学習結果をまた全員に分配することで、全員が全参考書を読んで賢くなったようにしてしまう。そして、またそれぞれが別の参考書で学習すれば、また賢くなっていく。これを繰り返せば、相当な速度で賢くなるはず。
一人でやるより、二人でやれば2倍近く賢くなり、4人、8人、16人、、、、と増やしていくと、賢くなる速度が倍々で速くなるはずだ。
でも、そんなにうまくいくだろうか。
ということで調べていたら、こんな記事にぶち当たった。
ChainerMN による分散深層学習の性能について
そして、この中には、以下のグラフが含まれていた。
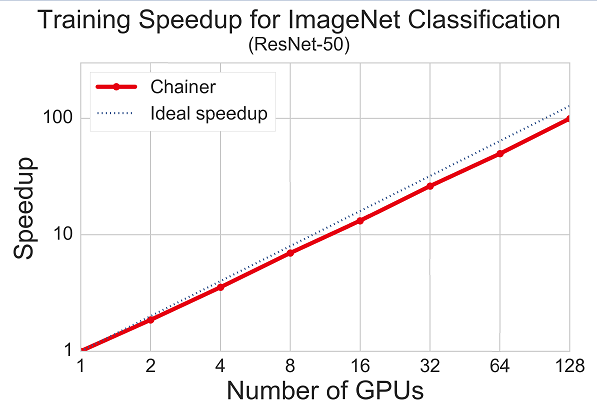
GPUを128個使うと、100倍高速になったとある。
つまり、ほぼGPUの数に比例して高速になるという夢のような効率である。
本当にそこまで高速になるのか、どうしても疑いたくなってしまう。
さらに、他のフレームワークとのスケーラビリティの比較があった。
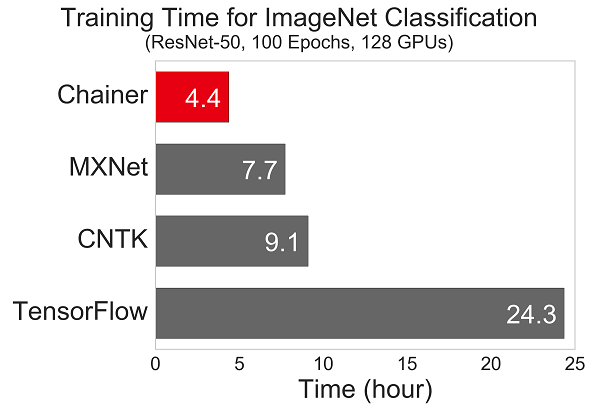
ChainerはPythonなので、単純比較してしまうと高速ではないはずだ。
しかし、GPUをたくさん使った場合には、他のDeep Learning よりも遥かに高速になるらしい。
以上は、Chainerを作っているPrefered NetworksのPreferred Researchにあったものの引用である。
もっと詳しく知りたい場合は、ぜひオリジナルを読んでみよう。
このGPUのマルチノード対応パッケージは、既に公開されているので、GPUがゴロゴロしている人、GPUをふんだんに使える環境にある場合は、ぜひ実験してみよう。
詳細は、分散深層学習パッケージ ChainerMN 公開 で確認のこと。
時間だけでなく、メモリもいっぱい必要になる。
今はGPUなるものがあり、これを使うと計算処理が一気に早くなると言われている。
GPUの計算性能は、CPUの50倍以上とか言われているのだが、実際にはそこまで高速にDeep Learningできるようにはならない。
GPUを使う場合には、GPUにデータを送ったり、GPUからデータを受け取ったりなど、CPUとGPUの間でのデータのやり取りが発生し、この量が半端ではない。このため、実際の速度向上は10倍程度にしかならない。
でも、もっと高速にしたいと思ったらどうすればよいだろうか。
多数のGPUを同時に使えば、どんどん高速になるのではないだろうか。
分散して学習する場合に問題になるのは、別々のGPUで学習した結果をまとめて、それをまた全GPUに分配し直すという作業が必要である。これをいかに上手にするかで性能が殆んど決まってしまう。
これは人間にたとえると、多人数で勉強をするにの、それぞれ別の参考書を読んで学習し、読み終わったら全員で学習結果を寄せ集めることでより賢くし、学習結果をまた全員に分配することで、全員が全参考書を読んで賢くなったようにしてしまう。そして、またそれぞれが別の参考書で学習すれば、また賢くなっていく。これを繰り返せば、相当な速度で賢くなるはず。
一人でやるより、二人でやれば2倍近く賢くなり、4人、8人、16人、、、、と増やしていくと、賢くなる速度が倍々で速くなるはずだ。
でも、そんなにうまくいくだろうか。
ということで調べていたら、こんな記事にぶち当たった。
ChainerMN による分散深層学習の性能について
そして、この中には、以下のグラフが含まれていた。
GPUを128個使うと、100倍高速になったとある。
つまり、ほぼGPUの数に比例して高速になるという夢のような効率である。
本当にそこまで高速になるのか、どうしても疑いたくなってしまう。
さらに、他のフレームワークとのスケーラビリティの比較があった。
ChainerはPythonなので、単純比較してしまうと高速ではないはずだ。
しかし、GPUをたくさん使った場合には、他のDeep Learning よりも遥かに高速になるらしい。
以上は、Chainerを作っているPrefered NetworksのPreferred Researchにあったものの引用である。
もっと詳しく知りたい場合は、ぜひオリジナルを読んでみよう。
このGPUのマルチノード対応パッケージは、既に公開されているので、GPUがゴロゴロしている人、GPUをふんだんに使える環境にある場合は、ぜひ実験してみよう。
詳細は、分散深層学習パッケージ ChainerMN 公開 で確認のこと。

#人気の記事
#タグ


