データ解析のための統計モデリング入門 GLMの応用範囲をひろげる 読書メモ2
2017年 04月 11日
このブログ記事は『データ解析のための統計モデリング入門』(久保拓弥 著、岩波書店)という、とても分かりやすい統計モデリングの入門書を、さらに分かりやすくするために読書メモをまとめたものです。
今回は第6章、GLMの応用範囲をひろげるについてのまとめの二回目です。
この章では様々なタイプのGLMについて説明がされています。
まずはロジスティック回帰について説明されています。
なので、いろいろなパラメータについてロジスティック回帰のモデルをプロットしてくれるコードを用意しました。
コードはRで書きました。
N <- 20
linkFunction <- function(b1, b2) {
function(x) {
1 / (1 + exp(-b1 - b2 * x))
}
}
distribution <- function(x, linkFunction) {
l <- match.fun(linkFunction)
function(y) {
dbinom(y, N, l(x))
}
}
xs <- seq(0, 10, by = 2)
ys <- 0:N
xl <- "y"
yl <- "Probability"
legends <- paste0("x = ", xs)
for (b1 in seq(-0.5, 0.5, by = 0.2)) {
for (b2 in seq(-0.5, 0.5, by = 0.2)) {
l <- linkFunction(b1, b2)
title <- paste0("q = 1 / (1 + exp(-(", b1, " + ", b2, "x)))")
plot(0, 0, type = "n", xlim = c(0, N), ylim = c(0.0, 1.0), main = title, xlab = xl, ylab = yl)
for (x in xs) {
d <- distribution(x, l)
lines(ys, d(ys), type = "l")
points(ys, d(ys), pch = x)
}
legend("topright", legend = legends, pch = xs)
}
}リンク関数はロジスティック関数です。
コードでは以下の部分です。
linkFunction <- function(b1, b2) {
function(x) {
1 / (1 + exp(-b1 - b2 * x))
}
}これが二項分布のパラメータの一つである事象の発生確率 q を与えます。
もう一つのパラメータは試行回数 N ですが、これは 20 にしました。
ということで、リンク関数のパラメータ b1 と b2 さえ与えれば、説明変数 x に対して応答変数 y の分布がどのように変化するかが分かります。
コードを実行すると様々な b1 と b2 の値に対してモデルをプロットします。
例えば下図のような図がプロットされます。
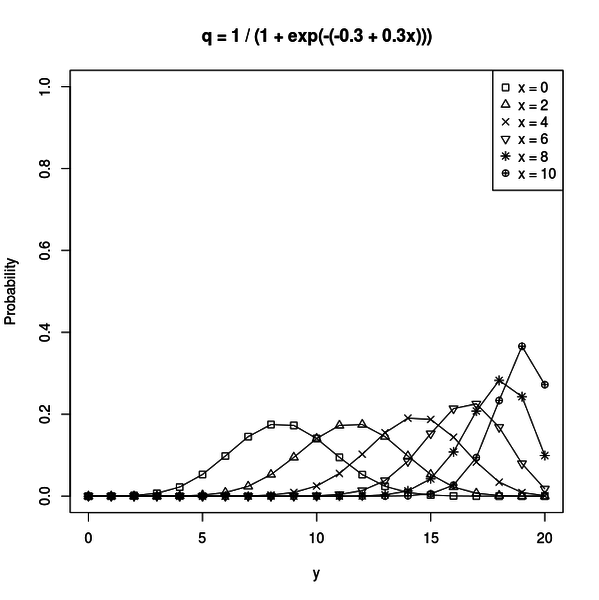
これは b1 = -0.3、b2 = 0.3 の場合です。x が 0 ならq = 1 / (1 + exp(0.3)) = 0.425... です。x が 10 ならq = 1 / (1 + exp(-2.7)) = 0.937... です。b2 が正なので x の増加に従って exp の引数部分がどんどん小さくなって、q 全体としては 1 に近づくわけです。
事象の発生確率が高くなれば、N 回の試行でその事象が起きる回数は大きくなります。
図を見ると、確かに x の増加に従って y の分布が大きな値を取るようになっているのが分かります。

#人気の記事
#タグ


