Deep Learningで利用する技術はまだまだあるらしい。
その中で、畳み込みとセットで使われることが多いのがPoolingなのだと。
ということで、以下の画像はスタンフォード大からのものである。
CS231n: Convolutional Neural Networks for Visual Recognition
がこの世界で非常に有名な講義であり、githubにあったものだ。
その中に、Pooling Layerという項目がある。
今回は、これを攻略してみようと思う。
Poolingにもいくつかのタイプがあるのだが、今回はよく使われているというmax pooling についてだ。
まず、Stanford大にあった説明図を示す。
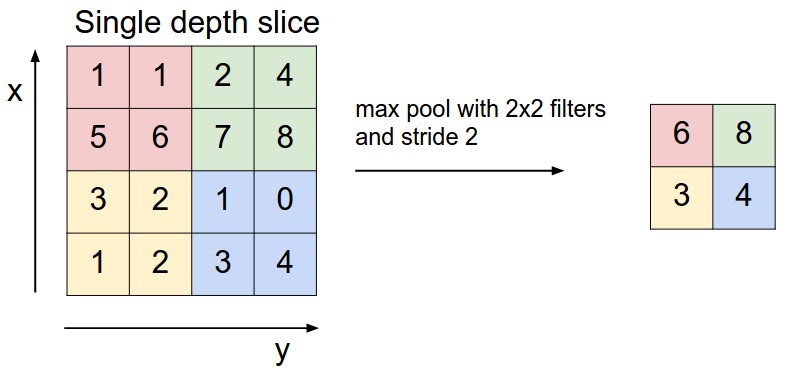 これは、2×2のフィルタのときの例である。
これは、2×2のフィルタのときの例である。
フィルタは正方形に限るようで、この場合、単にサイズ2という。
フィルタのサイズで、元の画像(配列データ)を区分けし、各区分けの中で一番大きい値を採用するものだ。
これは最大値を採用しているが、平均値を使うものもあり、average pooling と呼ぶ。
サイズ2のフィルタだと、縦、横1/2になり、全体で1/4になる。つまり、入力に比べてかなり小さくなる。
サイズ3のフィルタだと、縦、横1/3になり、全体で1/9になる。
つまり、データがかなり小さくなる。
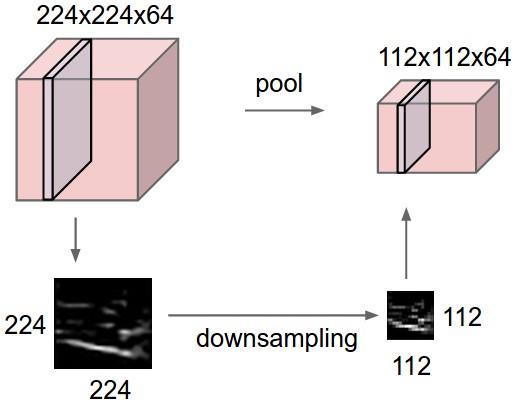
上の図は1チャネルだけを示しているが、実際のデータは多数のチャネルが重なっているので、次図のようになる。
その中で、畳み込みとセットで使われることが多いのがPoolingなのだと。
ということで、以下の画像はスタンフォード大からのものである。
CS231n: Convolutional Neural Networks for Visual Recognition
がこの世界で非常に有名な講義であり、githubにあったものだ。
その中に、Pooling Layerという項目がある。
今回は、これを攻略してみようと思う。
Poolingにもいくつかのタイプがあるのだが、今回はよく使われているというmax pooling についてだ。
まず、Stanford大にあった説明図を示す。
これは、2×2のフィルタのときの例である。フィルタは正方形に限るようで、この場合、単にサイズ2という。
フィルタのサイズで、元の画像(配列データ)を区分けし、各区分けの中で一番大きい値を採用するものだ。
これは最大値を採用しているが、平均値を使うものもあり、average pooling と呼ぶ。
サイズ2のフィルタだと、縦、横1/2になり、全体で1/4になる。つまり、入力に比べてかなり小さくなる。
サイズ3のフィルタだと、縦、横1/3になり、全体で1/9になる。
つまり、データがかなり小さくなる。
上の図は1チャネルだけを示しているが、実際のデータは多数のチャネルが重なっているので、次図のようになる。
この操作により、データのボリュームはぐんと小さくなる。
ということは、大切な情報、微妙な情報が抜け落ちてしまい、結果が悪くならないだろうか?
という懸念が当然起きると思うが、皆さん使っているようなので、多分大丈夫なのだろう。
次回、やってみよう。
ということは、大切な情報、微妙な情報が抜け落ちてしまい、結果が悪くならないだろうか?
という懸念が当然起きると思うが、皆さん使っているようなので、多分大丈夫なのだろう。
次回、やってみよう。

#人気の記事
#タグ


